Data Flow Analysis in Compiler Design Techniques
Data flow analysis in compiler design is a fundamental technique used to gather information about the potential values of variables at various points in a program. This analysis helps in optimizing code, detecting potential runtime errors, and ensuring efficient memory usage. It is achieved through various methods, such as reaching definitions, live variable analysis, and constant propagation. The main goal is to improve the performance and safety of the generated code. Data flow analysis also plays a significant role in other advanced compiler optimizations, including loop optimization and dead code elimination. Understanding these techniques is essential for designing efficient compilers that produce high-performance code.
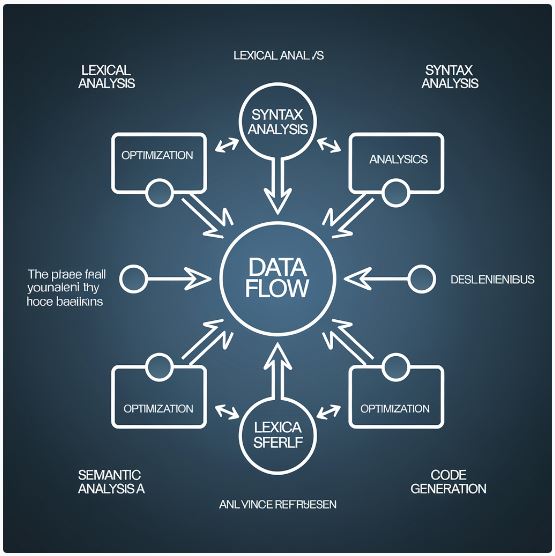
Introduction to Data Flow Analysis
Data flow analysis (DFA) is a critical aspect of compiler design that involves tracking the flow of data values through the variables of a program. This analysis provides valuable insights into the possible values of variables at different points in the program, which is crucial for optimizing code and enhancing runtime efficiency. Compilers use data flow analysis to perform optimizations, such as removing redundant code, allocating registers effectively, and eliminating dead code.
What is Data Flow Analysis?
Data flow analysis is a framework that uses mathematical methods to determine the values that different program variables can take at different points in the program’s control flow. This analysis is performed statically, meaning it is done at compile time, without running the program. The primary aim of DFA is to gather information about the values of program variables and how these values propagate throughout the program’s execution.
Key Concepts in Data Flow Analysis
To understand data flow analysis, it’s essential to grasp some foundational concepts:
- Control Flow Graph (CFG): A CFG is a representation of all paths that might be traversed through a program during its execution. Nodes in a CFG represent basic blocks, which are sequences of consecutive statements or instructions with a single entry and exit point. Edges between nodes represent the flow of control between blocks.
- Basic Block: A basic block is a straight-line code sequence with no branches, except at the entry and exit. It forms the nodes of the CFG and serves as the unit of analysis for many data flow algorithms.
- Data Flow Equations: These equations describe how data flows between basic blocks in a CFG. They are used to express the relationship between the input and output data of each block, often using sets or bit vectors to represent data states.
- Flow Functions: Flow functions define the transformation of data as it moves through the program. They determine how the state of data variables is modified by the instructions in a basic block.
- Meet Operator: The meet operator combines data from different paths in the control flow graph. In a forward analysis, it is typically the union or intersection operator, depending on the problem domain.
Types of Data Flow Analysis
Several types of data flow analysis are commonly used in compiler design:
if you are interested in data analyst roadmap read our effective article
- Reaching Definitions Analysis: This analysis determines which definitions of variables can reach a particular point in the program. A definition of a variable is a point where the variable is assigned a value. The key idea is to determine, for each point in the program, which variable definitions could be used without being redefined.
- Live Variable Analysis: Live variable analysis identifies variables that hold values that might be used in the future. A variable is considered “live” at a point in a program if its value is used along some path starting at that point. This analysis helps in register allocation and dead code elimination.
- Available Expressions Analysis: Available expressions analysis determines which expressions have already been computed and have not been invalidated by subsequent assignments. This is useful for optimizing redundant computations in code by reusing previously computed values.
- Constant Propagation: Constant propagation analysis identifies expressions that always yield a constant value. It replaces variables with their constant values wherever possible, leading to more optimized and efficient code.
- Very Busy Expressions: An expression is “very busy” if it is computed on every path from the current point to the exit without being invalidated. This analysis helps in deciding which expressions to compute early to avoid redundant calculations later.
Steps in Data Flow Analysis
Data flow analysis typically involves the following steps:
- Construct the Control Flow Graph (CFG): Build a CFG for the program, identifying all basic blocks and their relationships.
- Initialize Data Flow Information: Assign initial values to data flow variables. For example, in live variable analysis, all variables are initially considered dead.
- Iterative Analysis: Apply data flow equations iteratively to propagate information through the CFG until a fixed point is reached, meaning no further changes occur in the data flow values.
- Interpret Results: Use the results of the analysis to perform optimizations such as dead code elimination, constant propagation, or register allocation.
Applications of Data Flow Analysis in Compiler Design
- Data flow analysis is instrumental in several compiler optimizations:
- Dead Code Elimination: Removes code that does not affect the program’s observable behavior. For instance, if a variable’s value is never used, the assignment to that variable can be removed.
- Loop Optimization: Improves the performance of loops by moving invariant computations outside the loop or by eliminating unnecessary loop iterations.
- Register Allocation: Determines the optimal usage of CPU registers by understanding which variables are live at different points and assigning them to registers accordingly.
- Instruction Scheduling: Reorders instructions to improve pipeline efficiency in modern processors without altering the program’s behavior.
Challenges in Data Flow Analysis
Despite its benefits, data flow analysis faces several challenges:
- Scalability: Analyzing large programs with complex control flows can be computationally expensive and may require sophisticated algorithms and data structures to manage efficiently.
- Precision vs. Efficiency: There is often a trade-off between the precision of the analysis and its efficiency. More precise analyses can yield better optimization but at the cost of increased computation time.
- Handling Aliases: In languages with pointers or references, aliasing can complicate data flow analysis, as it is difficult to determine the exact variable being referenced.
Conclusion
Data flow analysis is a fundamental technique in compiler design that enables various optimizations and improvements in code generation. By understanding the flow of data within a program, compilers can enhance performance, reduce memory usage, and eliminate unnecessary computations. For anyone involved in compiler design, mastering data flow analysis is essential for developing efficient and optimized software.
Suggested Readings
- Pointer Analysis: Handling pointers and references in data flow analysis for languages like C/C++.
- To gain a deeper understanding of data flow analysis and its applications in compiler design, consider reading the following topics:
- Control Flow Analysis and Optimization: Understanding how control flow impacts data flow and optimization strategies.
- Advanced Compiler Design Techniques: Exploring other optimization techniques such as loop unrolling, inline expansion, and software pipelining.
- Static Single Assignment (SSA) Form: Understanding the role of SSA in simplifying data flow analysis and optimization.
- Interprocedurally Data Flow Analysis: Analyzing data flow across function boundaries for whole-program optimization.